這篇文章將會接續上一篇「Edge Impulse 影像辨識實作:資料收集(Part 2)」。

在 Pixel:Bit 教學(五) 中我們介紹了什麼是 TinyML,在 TinyML 中 Edge Impulse 所扮演的角色,以及 Edge Impulse 提供了哪些服務,最後更帶大家從 Pixel:Bit 收集圖片資料,轉交 Edge Impulse 做初步的資料預處理及特徵提取。這個單元將帶大家繼續完成「模型訓練&驗證」、「模型測試」、「模型部屬」三個部分,達到實際使用 Pixel:Bit 實作影像分類的功能。
在 Pixel:Bit 教學(五) 文章中我們已經上傳四個類別(剪刀、石頭、布、背景)的資料,並經過 Edge Impulse 提供的特徵提取功能取出資料特徵值,接著我們需要將這些有用的資料進行遷移學習(Transfer learning)訓練。
遷移學習(Transfer learning)是屬於機器學習的一種研究領域,它專注於儲存已有問題的解決模型,並將其利用在其他不同但相關問題上;比如說,用來辨識汽車的知識也可以被用來提升識別卡車的能力,因此我們可容易的從既有已訓練的模型中繼承其經驗,讓它能以少量資料學習新事物。
接下來就依照以下步驟一起進行模型訓練:
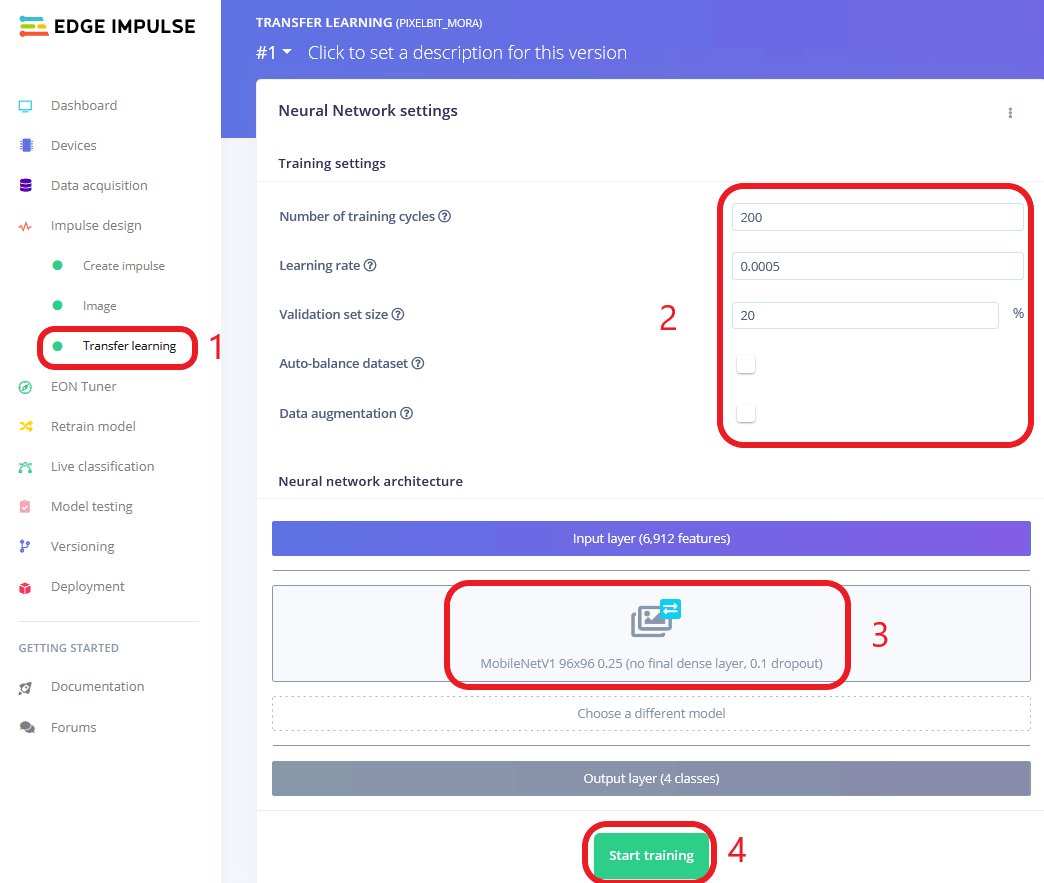
訓練完畢後我們可在頁面右側看到訓練完的準確度、損失及相關資訊,從下圖中我們可以看到此次訓練準確度達 86%,LOSS 0.34,並且可以看到每一類別的準確度,其中我們可以發現「剪刀(SCISSORS)」類別準確度最低只有 75%,有高達 18% 被認為是「布」類別(可能他們差異不大,難道是因為差三根手指頭而已??),但也還在可接受的範圍內;最後我們可在下方看到預估的「推論速度」、「RAM、FLASH使用量」,讓我們初步評估是否適合運行在目標裝置上。
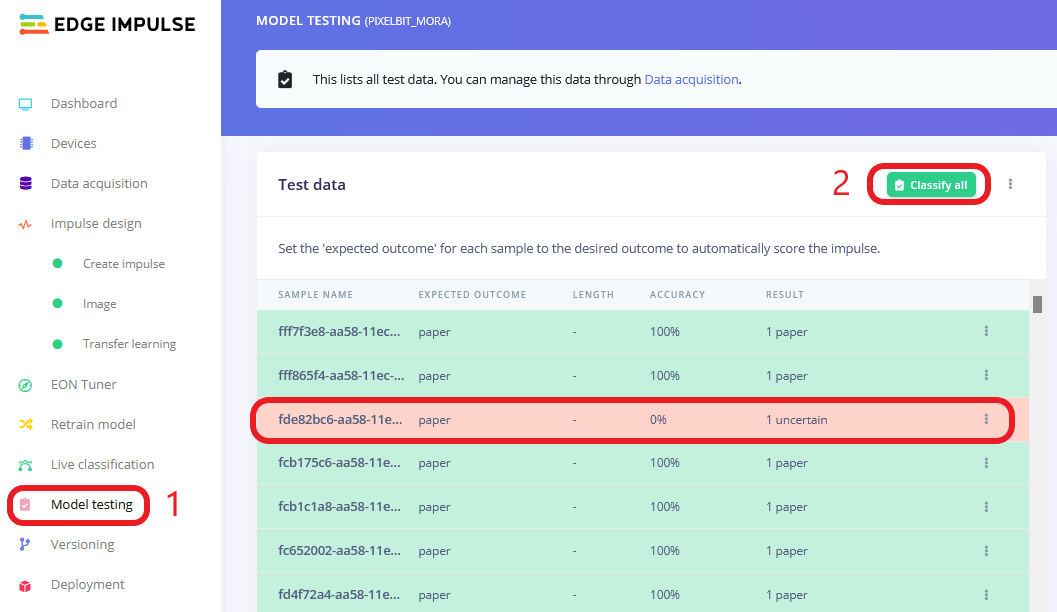
模型經過 Edge Impulse 訓練完成後接著就需要測試模型,還記得最初上傳圖片資料時我們選擇「自動拆分資料到訓練、驗證、測試階段」選項,所以每個階段會取各自的資料做處理,在訓練階段它將會針對訓練資料做訓練,訓練過程透過驗證資料驗證準確度。
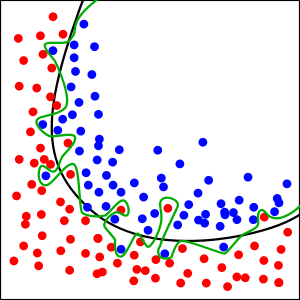
其中若我們沒有透過測試階段測試模型,單純只看訓練後驗證的準確度,就有可能會產生過擬合(如上圖)的問題,即誤以為模型訓練的結果似乎很好,能夠準確分辨所有事物,但其實模型只是學會了表面工夫,對於沒有學習過的資料實際上是一竅不通,所以最終我們還是需要進一步測試模型,以確保模型對於一些未知的資料也能夠擁有較高的辨識準確度。
分類完畢後我們可以看到有哪些資料分類錯誤,並且可以進一步查看或移動資料到訓練資料集內。
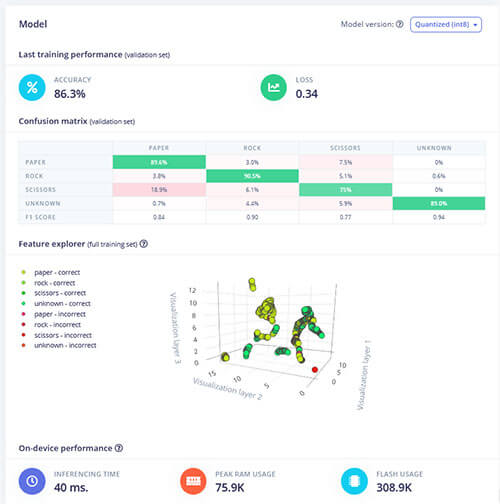
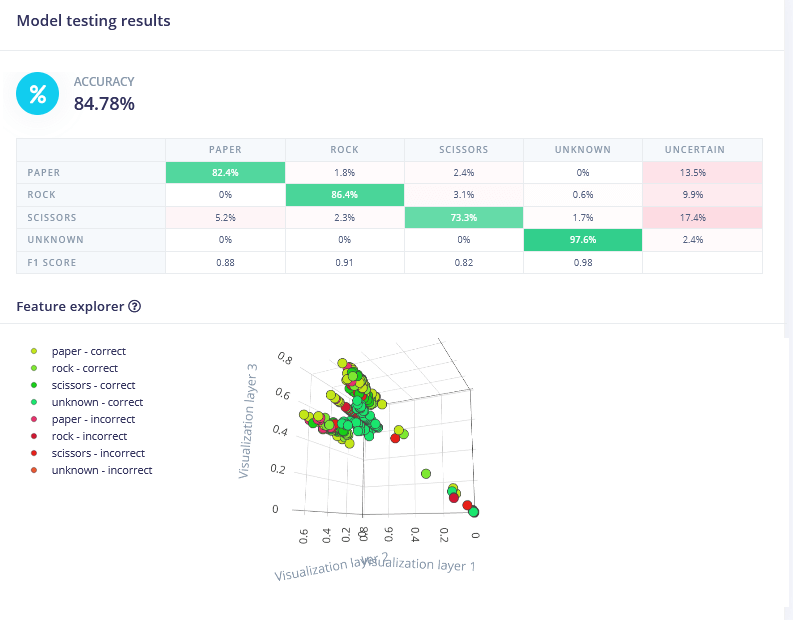
從下圖我們可看到整體分類後的準確度高達 84%,並且一樣是「剪刀」類別準確度最低,只有 73%,但也還在可接受的範圍內;整體準確度與訓練後驗證準確度相符,所以我們可以有比較高的信心認為此模型應該沒有問題。
請接續「Edge Impulse 影像辨識實作:模型訓練與使用(Part 2)」。

